链表解题技巧
理解指针或引用的含义
有些语言中有"指针"的概念,比如 C 语言,而在 Java 中取而代之的是"引用"。不论是指针还是引用,它们的意思是一样的,指存储所指对象的内存地址。接下来我们都以指针来讲解。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针;或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能够找到这个变量。
在编写链表代码的时候我们经常会有p.next = q,这行代码是说,p 结点中的next指针存储了 q 结点的内存地址。
警惕指针丢失和内存泄漏
不知知道你有没有这样的感觉,写链表代码的时候,指针指来指去,一会就不知道指到哪里了。所以我们在写的时候一定要注意不要弄丢了指针。
例如单链表的插入操作:
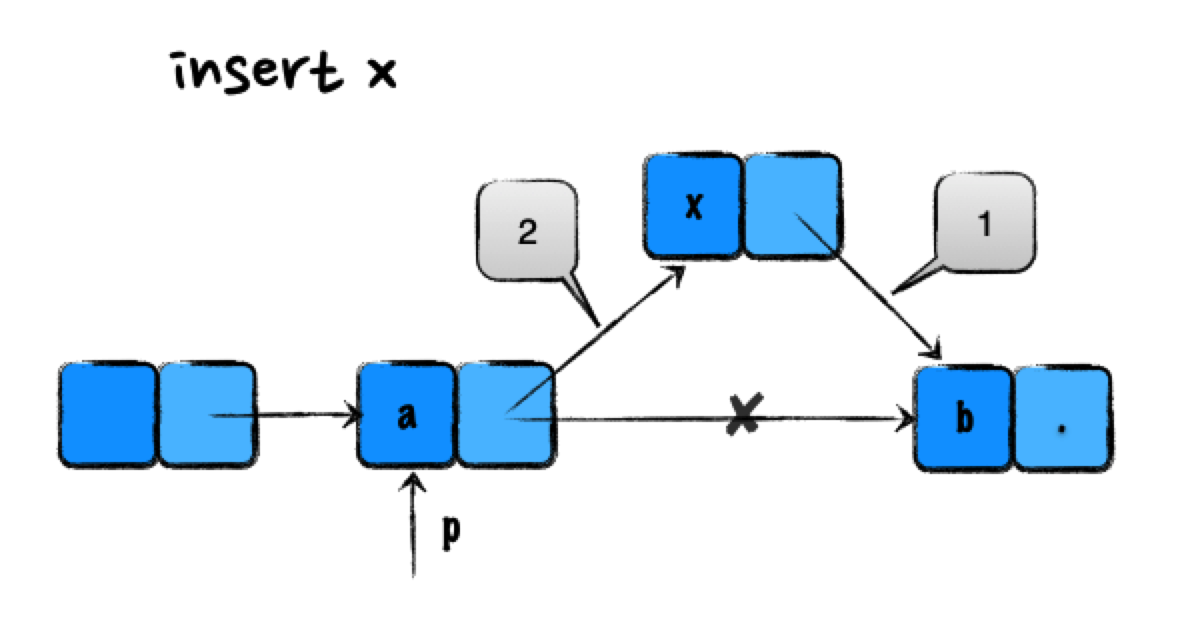
如图所示,在 a 结点后插入 x 结点。通过遍历器 p 找到 a 结点,如果代码写作:
p.next = x;
x.next = p.next;
这样会导致指针丢失和内存泄漏。在第一步操作完后,p 的next指针已经不再指向 b 结点,因此第二行相当于将 x 的next指针指向自己,而指向 b 结点的指针永远丢失了。正确的写法应该是:
x.next = p.next;
p.next = x;
此外,一定要记得手动释放内存,比如删除链表结点。如果是 Java 这类有虚拟机自动管理内存的编程语言就不需要考虑这么多了。
利用哨兵简化实现难度
哨兵(sentinel)解决国家边界问题,同理链表中加入哨兵也是为了解决边界问题。我们先看几个例子。
例如单链表插入操作。向 p 结点后面插入一个新结点:
new_node.next = p.next;
p.next = new_node;
但是如果是向空的链表中插入第一个结点,上述逻辑就不能用了。需要特殊处理一下:
if (head === null) {
head = new_node;
}
再如单链表删除操作。如果是删除 p 结点的后继结点,
p.next = p.next.next;
但如果是删除链表中的最后一个结点,上述逻辑就会有问题。仍然需要特殊处理:
if (head.next === null) {
head = null;
}
从上面几个简单的例子可以看出,每次针对第一个或者最后一个结点进行特殊处理,这样的代码繁琐且容易出错。如何解决这个问题呢?这就需要引入一个"哨兵",链表中的"哨兵"通常是新添加一个假的头节点(dummy head),这样使得链表在任何时候都不为空。这种链表称为带头链表。
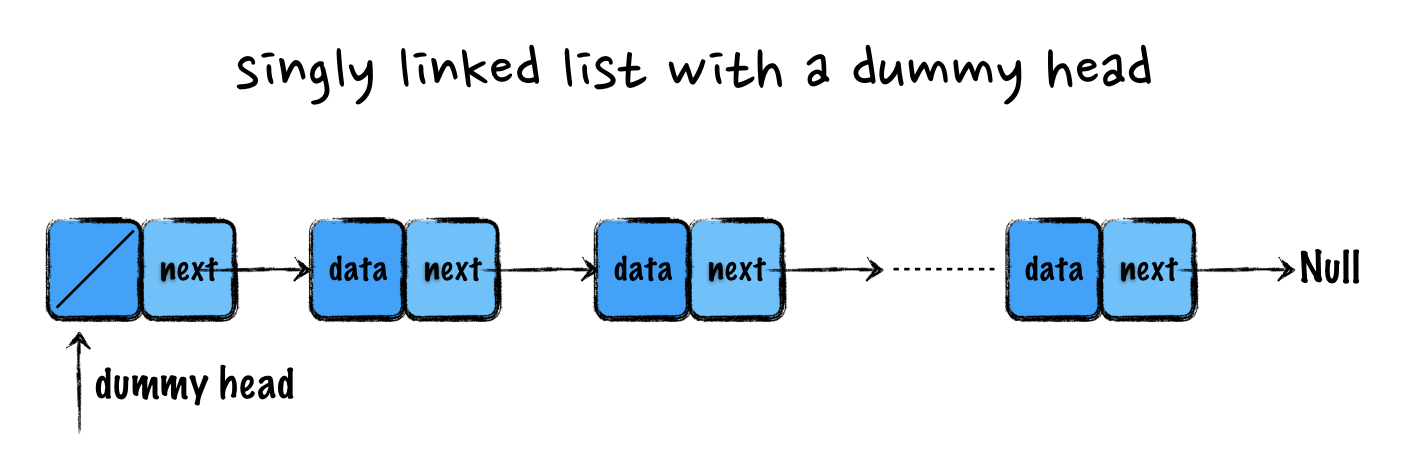
使用带头链表后,单链表插入和删除操作:
const ListNode = function (x) {
this.val = x;
this.next = null;
};
/**
* Add a node of value val before the index-th node in the linked list.
* If index equals to the length of linked list, the node will be appended to the end of linked list.
* If index is greater than the length, the node will not be inserted.
*/
const addAtIndex = function (head, index, val) {
let dummyHead = new ListNode(null);
dummyHead.next = head;
let cur = dummyHead;
for (let i = 0; i < index; i++) {
if (!cur) return head; // index out of bounds
cur = cur.next;
}
const newNode = new ListNode(val);
newNode.next = cur.next;
cur.next = newNode;
return dummyHead.next;
};
/**
* Delete the index-th node in the linked list, if the index is valid.
*/
const deleteAtIndex = function (head, index) {
let dummyHead = new ListNode(null);
dummyHead.next = head;
let cur = dummyHead;
for (let i = 0; i < index; i++) {
if (!cur) return head; // index out of bounds
cur = cur.next;
}
cur.next = cur.next.next;
return dummyHead.next;
};
使用带头链表后,双向链表的插入和删除操作:
const ListNode = function (x) {
this.val = x;
this.next = null;
this.prev = null;
};
/**
* Add a node of value val before the index-th node in the linked list.
* If index equals to the length of linked list, the node will be appended to the end of linked list.
* If index is greater than the length, the node will not be inserted.
*/
const addAtIndex = function (head, index, val) {
let dummyHead = new ListNode(null);
dummyHead.next = head;
let cur = dummyHead;
for (let i = 0; i < index; i++) {
if (!cur) return head; // index out of bounds
cur = cur.next;
}
const newNode = new ListNode(val);
newNode.next = cur.next;
cur.next.prev = newNode;
cur.next = newNode;
newNode.prev = cur;
return dummyHead.next;
};
/**
* Delete the index-th node in the linked list, if the index is valid.
*/
const deleteAtIndex = function (head, index) {
let dummyHead = new ListNode(null);
dummyHead.next = head;
let cur = dummyHead;
for (let i = 0; i < index; i++) {
if (!cur) return head; // index out of bounds
cur = cur.next;
}
cur.next = cur.next.next;
cur.next.prev = cur;
return dummyHead.next;
};
具体例子可以参考 删除链表倒数第 n 个结点。
双指针技巧
双指针主要有两种应用场景:
- 两个指针从不同位置出发: 一个从头出发,另一个从尾出发
- 两个指针以不同速度移动:一个指针快一些,另一个慢一些
- 两个指针从同一位置出发:一个先走到一定位置,另一个再出发
由于一般的链表只有后继指针,因此第一种场景不太适用。比较常用的是第二种和第三种。具体的算法可以参考判断链表中是否有环、链表的中间结点、删除链表倒数第 n 个结点
重点留意边界条件处理
经常用来检查链表代码的边界条件例如:
- 如果链表为空,代码能否正常工作
- 如果链表只含一个结点,代码能否正常工作
- 如果链表只含两个结点,代码能否正常工作
- 代码逻辑在处理头结点和尾结点时,能否正常工作
举例画图,辅助思考
对于比较复杂的链表操作,一会指这一会指那,很容易绕晕。这个时候可以使用举例法和画图法。可以找一个具体的例子,把它画在纸上,画出每部操作前后链表的变化,辅助思考。