大文件传输
前言
由前面的内容可知 HTTP 可以传输很多种类型的数据,例如文本、图片、音频和视频等。也就是说一个响应报文可能非常小到几B,也可能几GB。现在的网页可能包含大量的信息,随随便便一个主页 HTML 就有可能上百 KB,高质量的图片都是几十M,更不要说那些电影、电视剧了,几 G、几十 G 都有可能。那么 HTTP 是通过什么方法来解决这些大文件传输的呢?
数据压缩
通过数据压缩,可以减小实体数据的大小。例如当实体数据是100KB时,50%的压缩率,可以将数据能够压缩到 50K 的大小,这就相当于在带宽不变的情况下网速提升了一倍。
在请求头字段那一节曾经提到过Accept-Encoding头字段,它的参数是浏览器支持的压缩格式,例如:gzip、br等。这样服务器就可以根据Accept-Encoding的参数选择一种压缩算法,放进Content-Encoding响应头里,再把原数据压缩后发给浏览器。
不过这个解决方法也有个缺点,gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的,再用 gzip 处理也不会变小(甚至还有可能会增大一点),所以它就失效了。
数据压缩只用于文本类型数据传输
分块传输
上面提到了数据压缩只对文本有较好的压缩率,那其它媒体类型的大文件怎么传输呢?
在 HTTP/1.1 协议中提出了分块传输的概念,通过在响应报文中添加Transfer-Encoding: chunked来告知客户端报文实体数据不是一次性发过来的,而是分成了许多的块(chunk)逐个发送,当客户端收到所有数据后需要对数据进行拼装。
分块传输让客户端和服务器都不用在内存里保存文件的全部,每次只收发一小部分,网络也不会被大文件长时间占用,内存、带宽等资源也就节省下来了。
Transfer-Encoding: chunked和Content-Length这两个字段是互斥的,被分块的长度都是未知的
编码规则
分块传输采用的也是明文的方式,其编码规则如下:
- 每个“chunk”块包含长度头和数据块两个部分。
- 长度头是以 CRLF(回车换行,即\r\n)结尾,长度采用 16 进制。
- 数据块紧跟在长度头后,用 CRLF 结尾。
- 最后用一个长度为 0 的块表示结束,即“0\r\n\r\n”。
上述内容比较抽象,结合下图可以更好理解:

图:分块传输编码
分块编码传输可只应用于 HTTP/1.1 中,在 HTTP/2 中将采用数据流进行传输
范围请求
分块传输解决大文件传输的问题,但是还不够“灵活”。例如当我们看电影将电影的进度条拉到一半时,电影的前半部分内容显然是不需要的,我们期望的只是电影后半段这个“范围”的内容。HTTP 为了解决这个问题,提出了范围请求。
范围请求允许客户端通过Range: bytes=x-y获取资源 x 到 y 部分的内容,但是范围请求需要服务器的支持,服务器可以发送Accept-Ranges: bytes告知客户端支持范围请求,也可以发送Accept-Ranges: none,或者不发送“Accept-Ranges”字段告知客户端不支持范围请求。
也就是说,服务器收到 Range 字段后,需要以下四个步骤。
检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。服务器就会返回状态码“416 Range Not Satisfiable”。
如果范围正确,服务器就可以根据
Range头计算偏移量,读取文件的片段,返回状态码“206 Partial Content”。服务器需要添加一个响应头字段
Content-Range: bytes x-y/length,告知客户端片段的实际偏移量和资源的总大小。发送报文给客户端。
上述流程,如下图所示:
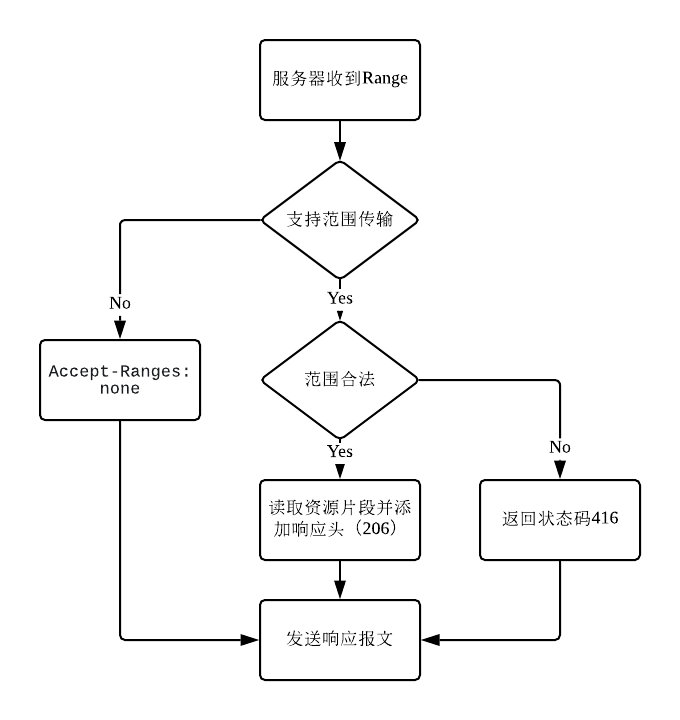
图:范围传输服务器判断流程
偏移量格式
Range: bytes=x-y中的 x、y 表示的是“偏移量”,例如前 10 个字节表示为“0-9”,第二个 10 字节表示为“10-19”。
Range 的格式也很灵活,起点 x 和终点 y 可以省略,能够很方便地表示正数或者倒数的范围。假设文件是 100 个字节,那么:
- “0-”表示从文档起点到文档终点,相当于“0-99”,即整个文件。
- “10-”是从第 10 个字节开始到文档末尾,相当于“10-99”。
- “-1”是文档的最后一个字节,相当于“99-99”。
- “-10”是从文档末尾倒数 10 个字节,相当于“90-99”。