请求头字段
概述
请求头字段是从客户端往服务器端发送请求报文中所使用的字段,用于补充请求的附加信息、客户端信息、对响应内容相关的优先级等内容。如一些请求头Accept, Accept-*表示内容协商, If-*表示条件请求,还有一些请求头字段如:User-Agent 和 Referer 描述了请求本身以确保服务端能返回正确的响应。常见的请求头字段如下图所示:

图:HTTP请求头字段
Accept*
Accept*类型的字段主要有Accept、Accept-Encoding、Accept-Language和 Accept-Charset。客户端在请求头里使用这些头字段与服务器进行“内容协商”,要求服务器返回最合适的数据。它们对应的实体头字段如下图所示:

图:Accept* 字段
Accept
Accept字段表示客户端可处理的媒体类型,当服务器收到Accept字段后,会通过Content-Type将实体的真实类型返告诉客户端。
Accept*类型的参数可以用“,”做分隔符列出多个类型,通过q=value来设置参数的权重,让服务器有更多的选择余地,例如下面的这个头:
Accept: text/html, application/xml;q=0.9, */*;q=0.8
对应的响应头:
Content-Type: text/html
它表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是 0.8。服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML。
HTTP 常见的媒体类型
- text:即文本格式的可读数据,我们最熟悉的应该就是 text/html 了,表示超文本文档,此外还有纯文本 text/plain、样式表 text/css 等。
- image:即图像文件,有 image/gif、image/jpeg、image/png 等。
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有 application/json,application/javascript、application/pdf 等。
Accept-Encoding
HTTP 在传输时为了节约带宽,有时候还会压缩数据,为了明确告知服务器优先返回那种实体编码格式,客户端会在请求头中添加Accept-Encoding字段。服务器收到Accept-Encoding字段后,会返回实体字段Content-Encoding来告知客户端使用那种方式解码实体数据。
Accept-Encoding的参数的设置;
Accept-Encoding: gzip, deflate;q=0.9, */*;q=0.8
对应的响应头中会包含Content-Encoding字段,即:
Content-Encoding: gzip
媒体类型数据常用编码类型:
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
- deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
- br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
Accept-Encoding 和 Content-Encoding 这两个字段是可以省略的,如果请求报文里没有 Accept-Encoding 字段,就表示客户端不支持压缩数据;如果响应报文里没有 Content-Encoding 字段,就表示响应数据没有被压缩。
Accept-Language
Accept-Language字段标记了客户端可理解的自然语言,例如:
Accept-Language: zh-CN, zh, en
这个请求头将告知服务器最好返回 zh-CN 的汉语文字,如果没有就用其它的汉语方言,如果还没有就返回英文。
服务器应该在响应报文里用头字段Content-Language告诉客户端实体数据使用的实际语言类型:
Content-Language: zh-CN
Accept-Charset
Accept-Charset字段标记了客户端可以使用的字符集,不过现在的浏览器都支持多种字符集,通常不会发送 Accept-Charset,服务器会根据请求头中的Accept-Language字段来判断客户端可以使用的字符集,并把实体字符集的类型放到Content-Type中返还给客户端,客户端可以通过Content-Type中的字符集推断出语言类型,所以服务器一般也不会发送Content-Language字段给客户端。
例如: 请求头中:
Accept-Language: zh-CN, zh, en
响应头:
Content-Type: text/html; charset=utf-8
请求头里一般不会包含Accept-Charset字段,只会有 Accept-Language 字段。而响应头里不会返回Content-Language字段,只会有 Content-Type 字段。
If-*
if-*类型的条件请求都是用来验证资源是否失效,常见的是,常用的是if-Modified-Since和If-None-Match,在缓存中收到状态码为 304 就代表命中协商缓存,可以复用缓存里的资源;If-Unmodified-Since,If-Match和If-Range这三个字段不常见,了解即可。
If-Modified-Since
if-Modified-Since的参数是 GMT 格式的时间,服务器拿到时间和资源的更新时间做对比,如果if-Modified-Since的时间早于资源的更新时间,服务器会将新的资源返回给客户端(状态码 200)。否则,服务不会接受请求,直接返回 304 状态码,此时客户端会读取缓存文件。
字段格式:
If-Modified-Since: Tue, 24 Dec 2019 12:29:40 GMT
If-None-Match
服务器通过获取请求头中If-None-Match的参数和标记资源的 Etag 的值做对比,如果值不相同时服务器处理请求,状态码为 200,返回新的资源给客户端。否则命中协商缓存,客户端读取本地资源。
If-Range
If-Range需要和Range字段一起使用,当If-Range的值和 Etag 的值匹配的时候,返回Range指定的部分资源,如果不匹配的时候,返回全部资源给客户端。
If-Unmodified-Since和If-Modified-Since的行为相反,If-Match的行为和If-None-Match的行为相反,两个字段了解即可。
Range
Range是 HTTP 范围请求的专用字段,格式是Range: bytes=x-y,其中的 x 和 y 是以字节为单位的数据范围。
服务器收到 Range 字段后必须检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。服务器就会返回状态码 416,告知客户端的范围请求有误,无法处理。
如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码206 Partial Content,和 200 的意思差不多,但表示 body 只是原数据的一部分,并把数据传送给客户端
对应的响应头中一般会添加Content-Range和Accept-Ranges字段。
其中Content-Range告知客户端片段的实际偏移量和资源的总大小,格式是Content-Range: bytes x-y/length与 Range 头区别在没有“=”,范围后多了总长度。例如,对于“0-10”的范围请求,值就是Content-Range: bytes 0-10/100。
Accept-Ranges字段用来告知客户端,服务器是否支持范围请求,当返回Accept-Ranges: bytes表示服务端支持范围请求。如果Accept-Ranges: none或者不返回该字段,表示服务器没有实现范围请求功能,只能收发整块文件。
Host
Host字段是唯一一个 HTTP/1.1 规范里要求必须出现的字段,也就是说,如果请求头里没有 Host,那这就是一个错误的报文。
Host 字段告诉服务器这个请求应该由哪个主机来处理,当一台计算机上托管了多个虚拟主机的时候(多台主机使用同一个 IP 地址),服务器端就需要用 Host 字段来选择,有点像是一个简单的“路由重定向”。

图:Host示意图
Referer
Referer 字段用来告知服务器请求的原始 URI,客户端一般都会发送Referer 字段给客户端,但有时 URL 中会包含一些敏感数据,此时可以不发送 Referer 字段。
Referer格式
Referer: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status/412
User-Agent
User-Agent是请求字段,只出现在请求头里。它使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以依据它来返回最合适此浏览器显示的页面。
但由于历史的原因,User-Agent非常混乱,每个浏览器都自称是“Mozilla”“Chrome”“Safari”,企图使用这个字段来互相“伪装”,导致 User-Agent 变得越来越长,最终变得毫无意义。
不过有的比较“诚实”的爬虫会在 User-Agent 里用“spider”标明自己是爬虫,所以可以利用这个字段实现简单的反爬虫策略。
Authorization
首部字段Authorization是用来告知服务器,用户代理的认证信息(证书值)。通常,想要通过服务器认证的用户代理会在接收到返回的401 状态码响应后,把首部字段 Authorization 加入请求中。
Authorization 的格式:
// Authorization: <type> <credentials>
Authorization: Bearer OiJKV1QiLCJhbGciOiJIUzI1NiJ9
其中type代表认证类型,credentials为认证凭证,在OAuth 2.0和JWT中代表对应的token。
客户端会通过在请求头中添加Authorization字段来进行身份验证,如下图所示:
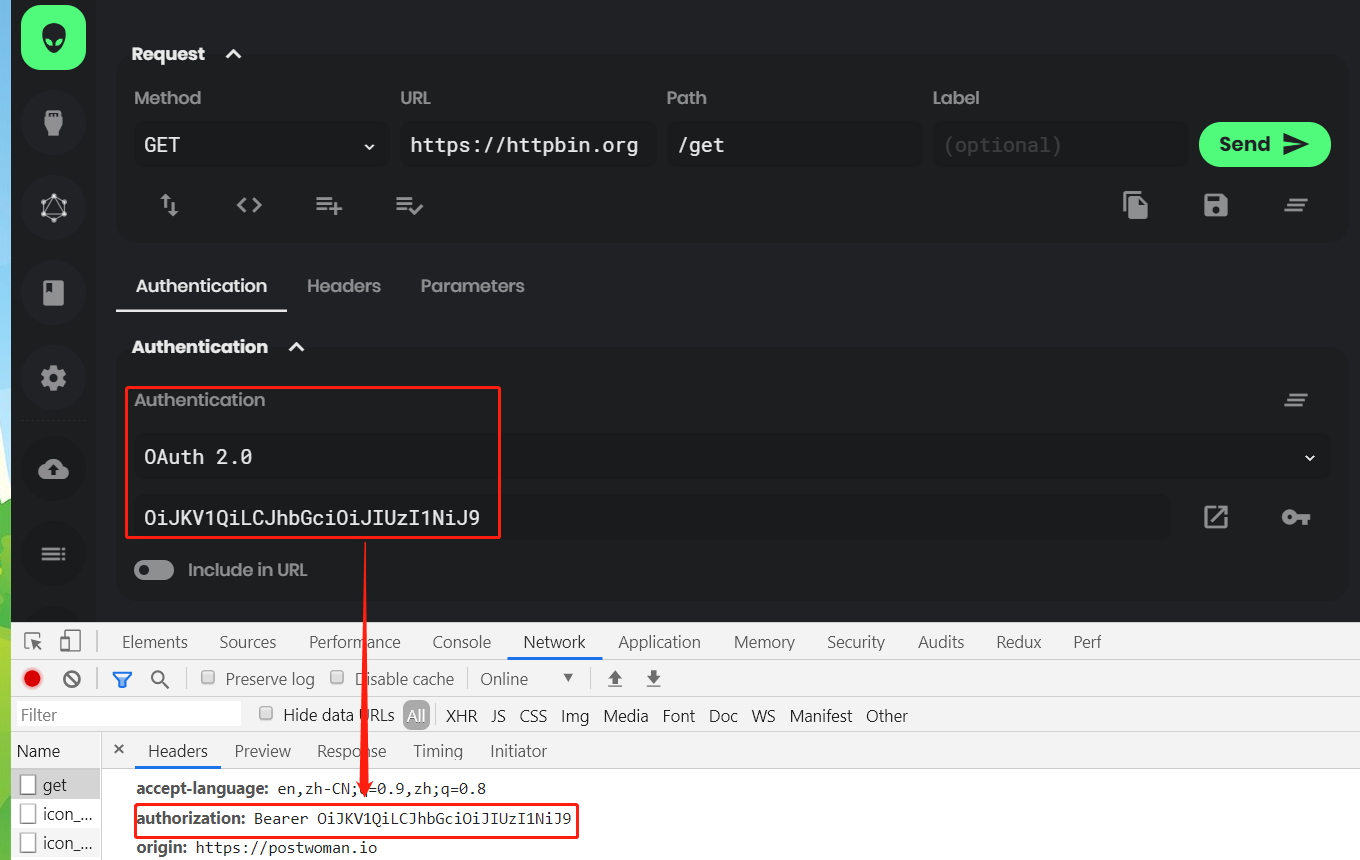
图:Authorization字段
上图使用postwoman工具,通过设置接口的OAuth 2.0的认证方法和token值,实现了用户的身份认证。
Proxy-Authorization
接收到从代理服务器发来的认证质询时,客户端会发送包含首部字段 Proxy-Authorization 的请求,以告知服务器认证所需要的信息。
这个行为是与客户端和服务器之间的 HTTP 访问认证相类似的,不同之处在于,认证行为发生在客户端与代理之间。客户端与服务器之间的认证,使用首部字段Authorization可起到相同作用。
Proxy-Authorization 的格式
Proxy-Authorization: Basic dGlw0jkpNLAGfFY5
其他字段
除了上述字段外还有Origin、Access-Control-Request-Methods、Access-Control-Request-Headers等字段,这些Access-Control-Request-*用在CORS跨域的预检请求报文中。关于这部分的内容可以参考文档中关于CORS。